 |
|
 |
|
MultiNet ist ein komplexer Formalismus, der eine differenzierte Bedeutungsdarstellung gestattet. Eine textuelle Darstellung des semantischen Netzes als gerichteter Graph inklusive aller dazugehörigen Attribut-Schichten wird jedoch bereits für kleine Netze sehr unübersichtlich. Dies verdeutlicht etwa die Scheme-Darstellung des Satzes "In Bayern herrscht heute schönes Wetter" in Abbildung 1.
(net ( |
Die Erfahrungen mit der Erstellung von semantischen Netzen und mit dem Einsatz von MultiNet in der Lehre zeigen, daß die graphische Notation von semantischen Netzen für den menschlichen Leser am einfachsten zu verstehen ist. Daher stellt MWR den Inhalt der Wissensbasis in einer graphischen Benutzeroberfläche dar. Inhalte der Wissensbasis können nach dem WYSIWYG-Prinzip (What you see is what you get) editiert werden, indem Knoten und Kanten direkt mit der Maus gezogen bzw. eingefügt werden. Abbildung 2 zeigt einen Screenshot der MWR-Benutzeroberfläche. Der Knoten "schön.1.1" ist gerade selektiert und wird daher blau angezeigt.
 |
Die Art und Weise, wie MWR eine MultiNet-Wissensbasis darstellt, kann vom Benutzer konfiguriert werden. So kann die Anzeige weitere Attribute aus dem MultiNet-Repertoire berücksichtigen. Das folgende Beispiel etwa zeigt zusätzlich die Sorten aller Knoten des Beispielnetzes.

|
Alle Netzelemente sind mit einem kontextsensitiven Popup-Menü ausgestattet. Über diese Menüs können weitere Informationen über die Netzelemente abgerufen werden (zum Beispiel eine Aufstellung aller vorhandenen Attribute). Das abschließende Beispiel dieses Abschnitts zeigt den Aufruf des "Layer"-Dialogs für den Knoten "gebietsinstitution.1.1". In dem erscheinenden Dialogfenster können die Layer-Attribute des Knoten verändert werden.
 |
Über die elementaren Operationen (wie z.B. das Erzeugen von Knoten) hinaus, unterstützt MWR den Aufbau und die Verwaltung von MultiNet-Wissensbasen durch weitere spezialisierte Editierungsfunktionen. Die folgende Abbildung zeigt die Zusammenfassung zweier Netzknoten zu einem einzelnen Knoten:

|
Zieht der Benutzer einen Netzknoten über einen bereits vorhandenen Knoten, so erscheint ein Dialog mit der Frage, ob beide Knoten zusammengefügt werden sollen. Bei positiver Beantwortung erbt der untere Knoten alle Kanten des oberen Knotens und der obere Knoten wird anschließend entfernt. Eine solche manuelle Identifikation von Knoten ist nützlich, um die referentielle Verflechtung einer Wissensbasis herzustellen, die aus verschiedenen Teilen zusammengesetzt wird. Diese Teile können beispielsweise Inhalte einzelner Sätze wiedergeben, die zu einer kohärenten Darstellung des Gesamttextes zu assimilieren sind.
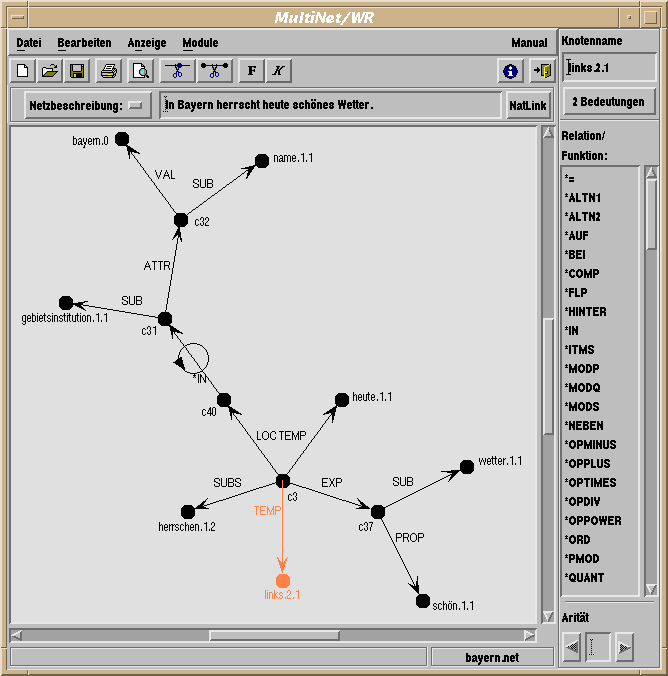
Der MultiNet-Formalismus bietet präzise Ausdrucksmittel zur Beschreibung der Bedeutung von Knoten und Kanten, wie etwa Layer-Attribute, ontologische Sorten und Wissenstypen (ktypes). Diese Beschreibungsmittel haben auch eine strukturierende Funktion, die eine Erkennung von Fehlern beim manuellen Editieren von Netzen und eine entsprechende Reaktion des Editors ermöglicht. So sind die Relationen (Kanten) per Definition nur mit bestimmten Konzepten (Knoten) kompatibel, während sie mit anderen nicht kombiniert werden dürfen. Ein typisches Beispiel sind die sortalen Anforderungen einer Relation an ihre Argumente. Derartige Kriterien können für automatische Konsistenzprüfungen genutzt werden, die immer dann ausgewertet werden, wenn der Benutzer den Inhalt der Wissensbasis verändert. Wie in Abbildung 6 gezeigt wird, erkennt MWR die Signaturverletzung, wenn versucht wird, eine Lokation ("links") an eine temporale Kante (TEMP) anzuschließen. Die betroffenen Knoten und Kanten werden orange eingefärbt, um den Ort der Signaturverletzung anzuzeigen.
 |
Zu den Netzkomponenten lassen sich über PopUp-Menüs Hilfetexte oder Ausschnitte aus der Online-Dokumentation aufrufen. Um der Inkompatibilität aus dem vorangegangen Beispiel auf den Grund zu gehen, kann der Benutzer beispielsweise über das Kontextmenü der TEMP-Kante eine Seite aus der Online-Dokumentation zur TEMP-Relation anzeigen lassen. Der in Abbildung 7 gezeigte Hilfetext für TEMP erklärt die Bedeutung der TEMP-Relation und spezifiziert formale Eigenschaften wie etwa die Signatur. Durch die Möglichkeit, zu allen MultiNet-Konstrukten Online-Hilfen einzusehen, können auch in MultiNet ungeübte Benutzer (z.B. Studenten) schnell einen Zugang zu MultiNet durch "learning by doing" finden.
 |
Zusätzlich zu den bisher vorgestellten Editierfunktionen, die sich auf einzelne Knoten oder Kanten beziehen, gibt es auch MWR-Werkzeuge, die auf ganzen Teilnetzen der Wissensbasis arbeiten. Es wird zwischen eingebauten und externen Werkzeugen unterschieden.
Eingebaute Werkzeuge sind Scheme-Programme, die über eine Plug-In-Schnittstelle in das MWR-System eingebunden werden. Ein Beispiel ist das Assimilationswerkzeug, das dazu dient, zwei Teilnetze zu einem Gesamtnetz zusammenzufügen, wobei referentielle Abhängigkeiten durch die Identifikation von Knoten aufgelöst werden. Um dieses Werkzeug anzuwenden, werden die zu assimilierenden Netze zunächst in zwei separaten MWR-Fenstern geladen (siehe Abbildung 8).
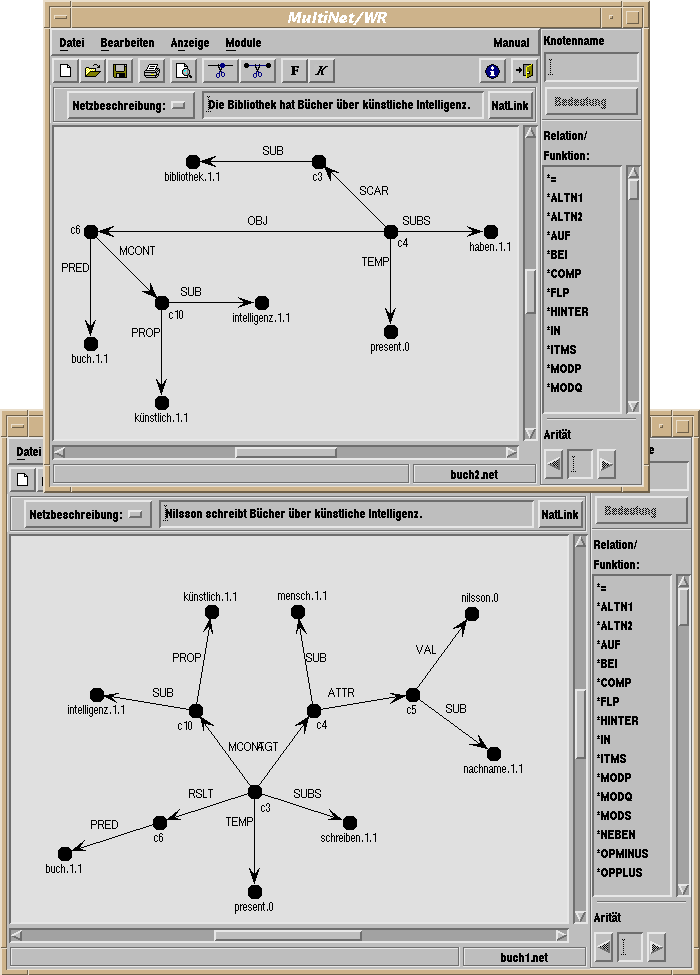 |
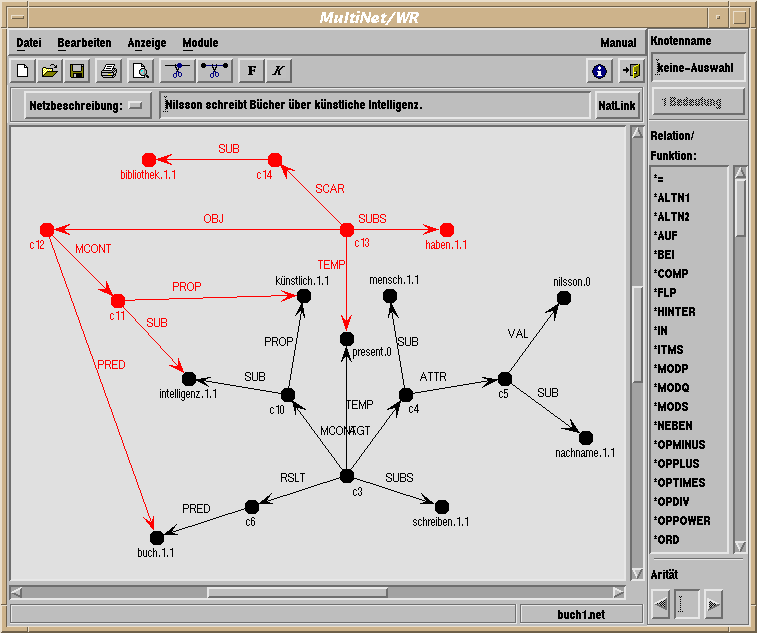
Die beiden Netze können dann durch den Aufruf des Assimilationswerkzeugs kombiniert werden. Um nachfolgende Korrekturen zu erleichtern, werden die Knoten und Kanten des Ergebnisnetzes dabei so eingefärbt, daß ihre Herkunft aus den ursprünglichen Netzen noch erkennbar ist.
 |
Zu den externen Werkzeugen zählt WOCADI, das eine wortklassengesteuerte Analyse natürlichsprachlicher Eingaben gestattet, und das Computerlexikon HaGenLex. Beide Systeme wurden ebenfalls auf der Basis von MultiNet entwickelt. Die Resultate dieser Komponenten können in die MWR-Wissensbasis integriert werden (siehe Abbildung 10).
 |
Natürlichsprachliche Sätze oder Phrasen können direkt in MWR eingegeben und durch Drücken des "NatLink"-Buttons an den WOCADI-Parser geschickt werden (siehe Eingabefeld im orange unterlegten Bereich des Screenshots). Das von WOCADI erzeugte Ergebnisnetz wird automatisch in die Wissensbasis von MWR übernommen und kann dort z.B. für Inferenzen genutzt werden.
Beim manuellen Hinzufügen von neuen Netzknoten in die Wissensbasis sieht MWR nach, ob ein passender Eintrag dazu bereits in HaGenLex vorhanden ist, und übernimmt ggf. die dortigen Attributeinträge für den Netzknoten. Außerdem informiert MWR den Benutzer, wenn zu einem Begriff mehr als eine Lesart vorliegt (im gelb unterlegten Bereich für "herrschen" gezeigt), und bietet dem Benutzer in diesem Fall eine Auswahl an.
Das MWR-System wird als Entwicklungsumgebung für weitere MultiNet-Anwendungen eingesetzt. Neue Anwendungen können sich auf die bereits vorhandenen Komponenten aus dem MWR-Baukasten stützen und das System um neue Funktionalität erweitern bzw. die MultiNet-Programmbibliothek weiter ausbauen.
Eine natürlichsprachliche Schnittstelle zu bibliographischen Datenbanken, die mit Hilfe der MWR-Programmierschnittstellen implementiert und dann als MWR-Plugin in das System integriert wurde, demonstriert den Nutzen von MWR zur Anwendungsentwicklung. Zur Realisierung des natürlichsprachlichen Zugangs wird die auf Deutsch formulierte Benutzeranfrage wird zunächst über die WOCADI-Schnittstelle in eine MultiNet-Darstellung übersetzt. Abbildung 11 zeigt die MultiNet-Analyse der Anfrage "Zeige mir Bücher von Nilsson über Künstliche Intelligenz".
 |
An dieser Stelle greift die Transformationskomponente an, die mit einem regelbasierten Ansatz Teilnetze der Fragedarstellung auf die Datenbankattribute der Zieldatenbank abbildet. Der Transformationsprozeß stützt sich auf die von MWR bereitgestellte Wissensbasis und Inferenzkomponente.
Der folgende Ausschnitt des Regelsystems hat die Aufgabe, mögliche Belegungen für das "Autor"-Attribut der bibliographischen Datenbank zu ermitteln:
;; ## Derive the author |
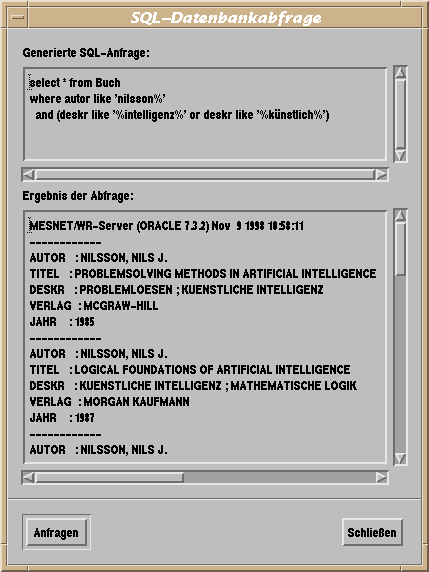
Die durch diesen Übersetzungsprozeß konstruierte formale Datenbankanfrage wird dann der Zieldatenbank zur Ausführung übermittelt. Abbildung 13 zeigt die erzeugte SQL-Anfrage zusammen mit dem Ergebnis der Datenbank.
 |
Das ursprüngliche
MWR-Werkzeug wird derzeit weiterentwickelt
und erweitert,
um neuen Anforderungen zu entsprechen.
Diese Arbeiten zielen u.a. auf eine Verbesserung der graphischen
Netzeditierung,
die Implementierung eines graphischen Axiomeditors und die
Unterstützung des kooperativen Editierens speziell
für die
Anwendung von MWR in der Lehre.
Insbesondere wird jedoch eine Erweiterung des MultiNet-Kerns
um neue Darstellungsmittel vorgenommen. Durch die Einführung
von
Bedeutungsmolekülen
kann der Wechsel zwischen
unterschiedlichen Bedeutungsfacetten eines Wortes modelliert werden.
Begriffskapseln
verfeinern die bisherige Trennung in
Wissensarten und verbessern die Modellierung von Einbettungen und
Quantifikation.