 |
|
 |
|
MultiNet ist ein Wissensrepräsentationsparadigma, dessen Eignung für die semantische Repräsentation natürlichsprachlicher Informationen über viele Jahre an der FernUni Hagen erprobt wurde. Den Kern von MultiNet bilden semantische Netze, die als gerichtete Graphen darstellbar sind. Knoten repräsentieren Konzepte aus dem Diskursbereich, während Kanten semantische Relationen zwischen den Konzepten wiedergeben. Zu den Knoten und Kanten gibt es mehrere Schichten ergänzender Attribute; diese Mehrschichtigkeit wird in der Namensgebung von MultiNet reflektiert.
Die auf dieser Seite vorgestellten Arbeiten zielen auf die Entwicklung von Wissensrepräsentationsmethoden für MultiNet und die Schaffung einer Arbeitsumgebung für Knowledge Engineering im Rahmen des MultiNet-Ansatzes.
Die Programmbibliothek zum Aufbau von MultiNet-Anwendungen wurde in der Programmiersprache Scheme implementiert. Sie umfaßt:
|
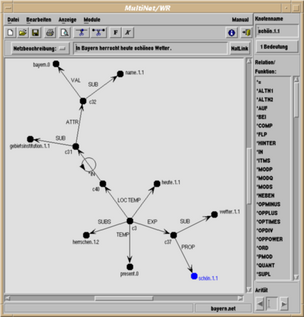
Das Knowledge-Engineering-Werkzeug MWR (Multinet WissensRepräsentation) unterstützt den Wissensingenieur bei der Arbeit mit MultiNet-Wissensbasen sowie bei der Erstellung von Anwendungen, die auf MultiNet aufbauen:
Eine graphische Benutzeroberfläche erlaubt das Browsen und Editieren von MultiNet-Wissensbasen nach dem WYSIWYG (What you see is what you get)-Prinzip. Automatische Konsistenzprüfungen und aus dem dargestellten Netz aufrufbare HTML-basierte MultiNet-Dokumentationen erlauben auch ungeübten Nutzern den Umgang mit dem MultiNet-Paradigma. Die graphische Benutzeroberfläche ist bzgl. des MultiNet-ADT vollständig, d.h. alles, was in dem MultiNet-ADT repräsentiert werden kann, ist auch auf dem Bildschirm darstellbar und veränderbar.
In MWR integriert sind zahlreiche Hilfsmittel zur Erstellung
komplexer Netze. Eine Assimilationshilfe unterstützt den
Benutzer beim Zusammenfügen mehrerer Einzelnetze. Dies wird
zum Beispiel bei der Repräsentation größerer
Textquellen erforderlich, die satzweise nach MultiNet
übersetzt worden sind.
Eine Layoutkomponente hilft beim übersichtlichen Anordnen
von automatisch generierten Netzen (z.B. aus der Analyse oder
aus einem Inferenzprozeß).
Über externe Schnittstellen bindet MWR das
ebenfalls am Lehrgebiet entwickelte
WOCADI-Werkzeug
für die wortklassenbasierte Analyse (WCFA) sowie das
Computerlexikon
HaGenLex
an. Dies ermöglicht es, natürlichsprachliche Analyse und
lexikalisches Wissen in die
Erstellung von MultiNet-Wissensbasen mit einzubeziehen.
MWR stellt eine integrierte Entwicklungsumgebung für MultiNet-basierte Anwendungen dar. Die obengenannte Wissensrepräsentation mit ihrem abstrakten Datentyp sowie die Inferenzkomponente sind Bestandteile des MWR-Systems. Neue MultiNet-Anwendungen können als Plug-Ins innerhalb des Systems implementiert werden; hierfür stehen neben der Wissensrepräsentation auch alle anderen Dienste und Werkzeuge der neuen Anwendung zur Verfügung. Über die graphische Benutzeroberfläche können Ergebnis-Netze der neu entstehenden Anwendung überprüft und spezielle Netze als Testeingaben generiert werden.
Mehr Informationen zur graphischen Benutzeroberfläche und zur Bedienung von MWR gibt die Kurztour des MWR-Systems. Die Tour stellt die wichtigsten Komponenten von MWR anhand von Screenshots vor und erläutert die Verwendung von MWR als Plattform für die Entwicklung von MultiNet-basierten Anwendungen.
[Publikationen des IICS-Gruppe]