

Wissensrepräsentation
mit Mehrschichtigen Erweiterten
|
||
| hermann.helbig@fernuni-hagen.de |
Den Kern der Wissensbasis bildet ein semantische Netz (SN), dessen Knoten Begriffe und dessen Kanten Beziehungen zwischen den Begriffen (genauer: Relationen und Funktionen) repräsentieren (s. hierzu auch die Werkbank für den Wissensingenieur MWR). Die Knoten sind bestimmten Sorten eines vorgegebenen Klassifikationssystems, einer sogenannten Ontologie, zugeordnet und werden entsprechend verschiedener semantischer Dimensionen durch Merkmale und deren Werte charakterisiert.Abb. 1: Einbettung der Darstellungsmittel in die Wissensverarbeitungskomponenten

Die Ontologie von
vordefinierten Sorten zeigt die Abb. 1a
(entsprechend
der oberen Schicht aus der Hierarchie von MultiNet-Konzepten, die durch
die Relationen SUB und SUBS definiert wird):

Für die Beschreibung der Darstellungsmittel von MultiNet gibt es eine umfangreiche Dokumentation. Abb. 2 vermittelt einen Eindruck von der Methodik nach der die etwa hundert Relationen und Funktionen von MultiNet beschrieben werden. Diese digital verfügbaren Beschreibungen stehen auch als Online-Hilfe in den Werkzeugen für die Wissensverarbeitung zur Verfügung.
CAUS: Kausalbeziehung, Relation zwischen Ursache und Wirkung
CAUS: si' × si' (Signatur stützt sich auf Sorten der Begriffsontologie)
- Definition
- Die Relation (s1 CAUS s2) gibt an, daß die reale Situation s1 Ursache für die reale Situation s2 ist.1 s2 ist die tatsächlich von s1 hervorgerufene Wirkung. Die Relation CAUS ist transitiv, asymmetrisch und nicht reflexiv.
- Mnemonik
- cause - Ursache
- Fragemuster
- {Warum/Wieso/Weshalb/Weswegen}
<s2>?
{Woran/An <WM>} {[sterben]/[leiden]/[erkranken]/...} <d>?
Wodurch [verursacht werden] <s2>?
Worin liegt die Ursache für <s2>?
Welche Wirkung {hat/hatte} <s1>?
{Dank/Aufgrund} <WS> <s1> {[geschehen]/[eintreten]/...} <s2>? - Kommentar
- Die
Kausalitätsbeziehung steht in engem Zusammenhang zur
Zeitrelation
ANTE, da die Wirkung zeitlich nicht vor der Ursache liegen kann:
(x CAUS y)
Zwischen den Relationen CSTR und CAUS besteht folgende Beziehung: ¬(y ANTE
x) (1)
¬(y ANTE
x) (1)
(s1 CSTR d)
Als typisch für die Beschreibung einer Kausalbeziehung kann der Satz 3 unten angesehen werden. Er macht deutlich, daß durch CAUS im Gegensatz zu COND (Konditionalbeziehung) und IMPL (Implikation) immer faktische Sachverhalte, die durch das Merkmal [FACT = real] gekennzeichnet sind, miteinander verknüpft werden. s2
([(s2
AGT d)
s2
([(s2
AGT d) (s2
INSTR d)]
(s2
INSTR d)]  (s2
CAUS
s1))
(2)
(s2
CAUS
s1))
(2)
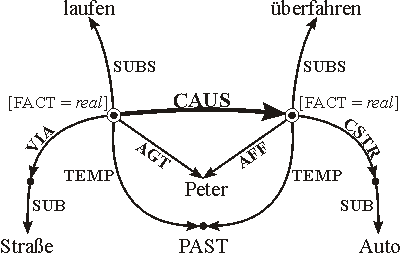
Abb. 2: Typisches Beschreibungsschema für eine Relation des MultiNet-Paradigmas
Wichtig für Wissensrepräsentationssysteme der KI, deren Wissensinhalte automatisch aus natürlichsprachlichen Informationen erschlossen werden sollen, ist die Verbindung der Bedeutungsrepräsentanten (Knoten des semantischen Netzes) mit den Wörtern der natürlichen Sprache. Diese Schnittstelle wird durch das Wörterbuch oder Lexikon gebildet (Ebene VIII in Abb.1), dessen semantische Komponenten (insbesondere die Valenzen der Verben, Adjektive und Nomen) ebenfalls mit den Darstellungsmitteln des semantischen Netzes formuliert werden (s. Werkbank für den Computerlexikographen LIA). Dadurch erhält man eine einheitliche Darstellungsform für sprachliches Wissen und "Weltwissen" (Erfüllung des sog. Homogenitätskriteriums).Zur Einordnung von Objekten, Situationen, Lokationen und Zeiten2 in einen mehrdimensionalen Raum von Merkmalen wird das Komplexmerkmal LAY (abgekürzt von "layers" - Schichten) benutzt. Letzteres umfaßt die Submerkmale: Generalisierungsgrad GENER, Faktizität FACT, Referenzdeterminiertheit REFER, Variabilität VAR, intensionale Quantifikation QUANT, Extensionalitätstyp ETYPE und (extensionale) Kardinalität CARD, die es gestatten, Begriffsrepräsentanten nach epistemologisch relevanten Gesichtspunkten zu klassifizieren und bestimmten Begriffsschichten zuzuordnen. Beispiele für die Einbettung von Konzepten in den durch diese Charakterisierungen aufgespannten Merkmalsraum sind in Abb. 3 angegeben.Abb. 3: Einbettung von Begriffsrepräsentanten in einen mehrdimensionalen Merkmalsraum

Die Vorstellung von "Schichten" in MultiNet steht in Analogie zu den Gegebenheiten im n-dimensionalen Euklidischen Raum. Wenn man dort entlang einer bestimmten Dimension einen Wert festhält (z.B. den Wert der z-Koordinate in einem dreidimensionalen Raum von Koordinaten x, y, z), dann erhält man eine (n-1)-dimensionale Ebene (im Beispiel eine Fläche parallel zur x-y-Ebene). Ähnlich ergibt sich durch Festhalten des Wertes eines bestimmten Layer-Merkmals (z.B. [GENER = ge]) die Ebene (Schicht) der generischen Begriffe, durch Festhalten des Wertes [FACT = hypo] erhält man die Ebene (Schicht) der hypothetisch angenommenen Sachverhalte bzw. der hypothetischen Objekte und durch Fixierung von [ETYPE = 1] und [GENER = ge] wählt man alle Kollektivbegriffe (hierzu gehört z.B. Gebirge, Vieh) aus usw.
Zur Darstellung des Bedeutungsumfangs eines
Begriffes benötigt man besondere Ausdrucksmittel, da es
anderenfalls
nicht möglich wäre, in einem semantischen Netz
anzugeben,
welche
relationalen Verbindungen (Kanten) einen bestimmten Begriff definieren
und welche lediglich auf den Begriff Bezug nehmen. In MultiNet
geschieht
die Eingrenzung des Begriffsumfangs durch das Konzept der Begriffskapsel
und
ihrer Komponenten (vgl. Abb.
4
a). In der bildlichen Darstellung
wird eine solche Kapsel durch ein abgerundetes Rechteck dargestellt,
das
entsprechend der verschiedenen Begriffskomponenten in mehrere Teile
untergliedert
ist.
In erster Instanz sind zwei verschiedene Bedeutungsanteile
hervorzuheben:
- Das immanente Wissen : Es umfaßt denjenigen Wissensanteil über einen Begriff, der unabhängig von der situativen Einbettung oder der Verwendung eines Begriffs zur Beschreibung eines bestimmten Sachverhalts ist. - In der bildlichen Darstellung wird das immanente Wissen durch helle bzw. dunkle Schattierung hervorgehoben.
- Das situative Wissen : Es umfaßt den Wissensanteil, der angibt, in welcher Weise ein Begriff in die Beschreibung bestimmter Situationen involviert ist. - Das situative Wissen wird in der bildlichen Darstellung innerhalb einer Kapsel durch fehlende Schattierung gekennzeichnet.
Zur Erläuterung soll der Begriff Haus herangezogen werden (vgl. Abb. 4b): Daß ein Haus bestimmte Teile (wie <ein Dach>, Mauern usw.) besitzt und ein Gebäude ist, kann als immanentes Wissen angesehen werden. Daß sich Peter ein Haus gekauft hat oder daß Häuser in München wieder teurer geworden sind, gehört nicht zum immanenten Anteil des Begriffsumfangs von Haus, sondern zum situativen Wissen, in dessen Beschreibung der Begriff Haus vorkommt.Abb. 4: Die verschiedenen Bedeutungskomponenten eines Begriffs

Innerhalb des immanenten Wissens lassen sich wiederum zwei verschiedene Anteile voneinander trennen und zwar ein kategorischer Anteil (diese Komponente ist im Bild dunkel schattiert und mit einem K gekennzeichnet) und ein prototypischer Anteil , auch Default-Anteil genannt, der aber a priori nur bei generischen Begriffen auftritt (diese Komponente ist im Bild hell schattiert und mit einem D gekennzeichnet).3 Das wesentliche Unterscheidungsmerkmal dieser Komponenten bezieht sich auf die inferentiellen Prozesse, die mit den verschiedenen immanenten Wissensanteilen verknüpft sind. Der kategorische Teil des Bedeutungsumfangs eines generischen Begriffs wird strikt (d.h. ohne Ausnahme) auf alle Unterbegriffe und subordinierten Spezialisationen vererbt (Träger dieser Vererbung sind die Relationen SUB und SUBS). Aus logischer Sicht sind also die Merkmalsaussagen des kategorischen Anteils mit einer Allquantifizierung verbunden. Wenn man die Darstellung in Abb. 4 für den Begriff Haus zum Ausgangspunkt nimmt, bedeutet dies, daß jedes spezielle Haus (<eine Villa >,<ein Lagerhaus>, <Pauls neues Haus> usw.) ein Gebäude ist, ein Dach besitzt und durch ein Baujahr charakterisiert werden kann.
Demgegenüber ist der prototypische Anteil des Bedeutungsumfangs eines generischen Begriffs als Default-Wissen anzusehen, das kategorische Wissen wird in der Begriffshierarchie von oben nach unten vererbt. Dabei versteht man unter einem Default eine grundsätzliche Annahme, die so lange gilt, wie keine anderslautende Information vorhanden ist. Sie kann aber im Gegensatz zum kategorischen Wissen in Ausnahmefällen revidiert oder überschrieben werden.
So ist es z.B. sinnvoll, für ein Haus anzunehmen, daß es Fenster und Türen hat oder daß es einem Besitzer gehört. Man kann sich aber durchaus Häuser vorstellen, die keine Fenster oder Türen aufweisen (ein Lagerhaus ohne Fenster, ein Pueblo-Haus ohne Türen, dafür mit einer Einstiegsluke usw.). Auch kann ein Haus herrenlos geworden sein, d.h. keinen Besitzer mehr haben usw. Aus dem Gesagten wird deutlich, daß das kategorische Wissen mit strikt monotonen Schlußweisen verknüpft ist, wie sie in der klassischen Prädikatenlogik gelten, während das prototypische Wissen durch nicht-monotone Schlußweisen charakterisiert wird, für die das Default-Reasoning typisch ist.
Für das MultiNet-Paradigma stehen Software-Werkzeuge zur Verfügung, die wesentliche Aspekte des Wissensmanagement, nämlich die Wissensakquisition, die Wissensrepräsentation und die Wissensmanipulation, unterstützen. Zu diesen Werkzeugen gehören:
- MWR - ein graphisches Nutzerinterface für den Wissensingenieur
- WOCADI
(NatLink) -
ein Analysesystem für die automatische
Übersetzung natürlichsprachlicher Ausdrücke
in
MultiNet-Strukturen - HaGenLex / LIA - eine Werkbank für den Computerlexikographen, die sich auf das MultiNet-Paradigma stützt.
- VILAB - das virtuelle elektronische Labor, welches unter anderem dazu benutzt wird, Studenten die Grundlagen von MultiNet zu lehren.
- Notes
- (1) Der Merkmalswert [FACT = real] wird durch einen Strich am Sortensymbol symbolisiert.
- (2) Für die anderen Sorten treffen die nachstehend behandelten Charakteristiken nicht zu.
- (3) Der Terminus Default-Wissen erklärt auch die Abkürzung D für den prototypischen Wissensanteil. Durch Vererbung kann auch ein Individualbegriff Default-Wissen übertragen bekommen (das bei Hinzutreten neuer Information überschrieben werden darf).
Publikationen des Lehrgebiets IICS
| MultiNet | MWR | WOCADI (NatLink) | VILAB | NLI-Z39.50 | HaGenLex / LIA |
Hermann Helbig - Leiter des Lehrgebiets Intelligente Informations- und Kommunikationssysteme - FernUniversität Hagen